大数据模块一学习路径与计划

大数据模块一学习路径与计划
dong zhou学习路径与计划
第一阶段:基础准备(1-2周)
Linux基础:
- 熟悉Linux命令行操作,包括文件管理、用户权限管理、网络配置等。
- 学习如何生成SSH密钥对,并实现免密登录,修改主机名,关闭防火墙。
数据库基础知识:
- 掌握SQL语言基础,包括数据表的创建、删除、修改及查询操作。
- 学习MySQL的基本使用,包括用户管理和权限设置。
第二阶段:环境搭建(3-4周)
JDK安装与配置:
- 在Linux环境下完成JDK的安装和环境变量配置。
- 使用
java -version和javac命令验证安装成功。
Zookeeper集群安装配置:
- 按照文档步骤,在master节点解压并配置Zookeeper,确保集群正常运行。
- 修改myid文件,配置各节点的ID。
- 启动Zookeeper并在各个节点查看状态。
Hadoop完全分布式集群搭建:
- 解压并配置Hadoop,包括namenode初始化、集群启动等过程。
- 配置Hadoop的core-site.xml、hdfs-site.xml、yarn-site.xml文件,确保集群正常运行。
- 初始化Hadoop namenode,启动Hadoop集群并检查各节点进程。
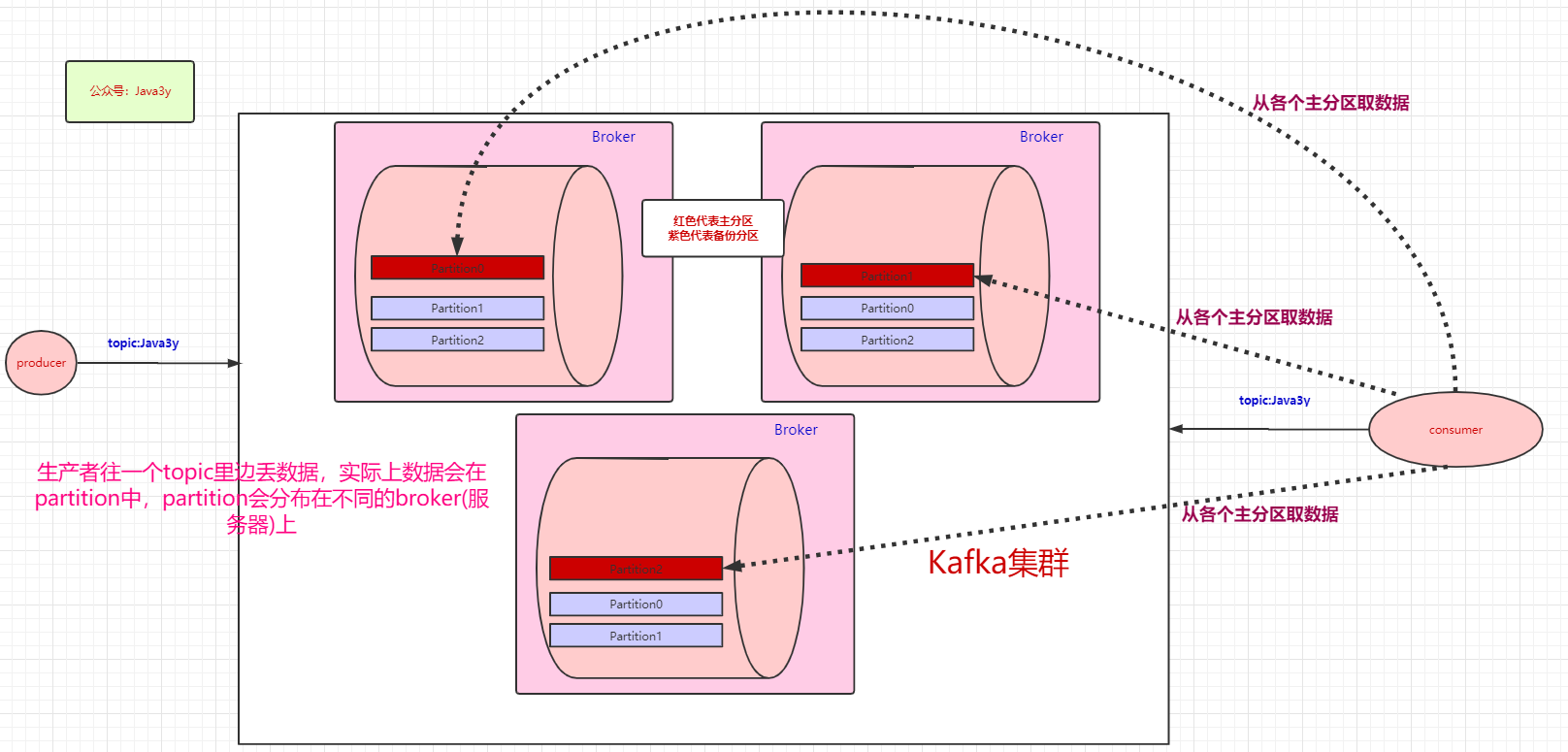
Kafka完全分布式集群搭建:
- 配置Kafka集群,确保其能与Zookeeper集成工作。
- 测试Kafka的消息发送与接收功能。
- 创建Topic,分区数为2,副本数为2,并测试创建成果。
第三阶段:高级组件配置(5-6周)
Hive安装配置:
- 将MySQL作为元数据库,并配置Hive以支持数据分析任务。
- 初始化Hive元数据库,并测试Hive的运行情况。
- 设置Hive环境变量,并使环境变量生效,执行命令
hive --version查看版本信息。
Flume安装配置:
- 配置日志收集系统,将其与Hadoop集成,用于实时数据处理。
- 启动Flume并查看其版本信息,确保配置正确。
- 使用Flume传输Hadoop日志,查看HDFS中生成的内容。
Flink on Yarn安装配置:
- 从Master中的
/opt/software目录下将文件flink-1.14.0-bin-scala_2.12.tgz解压到路径/opt/module中(如果路径不存在,则需新建)。 - 修改容器中
/etc/profile文件,设置Flink环境变量,并使环境变量生效。在容器中/opt目录下运行命令flink --version。 - 开启Hadoop集群,在YARN上以Per Job模式运行示例程序,如WordCount,并记录结果。
- 从Master中的
第四阶段:数据库管理与维护(7-8周)
数据库配置维护:
- 创建用户并分配权限。
- 数据库的导入导出操作。
- 使用SQL语句进行复杂的数据分析和报表生成。
数据表维护:
- 对已有的数据表进行增删改查操作。
- 维护数据表结构,添加新字段或修改现有字段。
第五阶段:项目实践(9-10周)
- 基于业务需求的数据分析:
- 根据实际业务需求,编写SQL查询语句,如统计特定时间段内温差超过一定阈值的城市。
- 分析酒店评论数据,计算评分,统计商圈内的酒店总数。
第六阶段:持续学习与优化(长期)
深入学习各组件原理:
- 如Hadoop的工作机制、Spark的RDD模型、Flink的流处理机制等。
- 学习如何监控集群状态,识别并解决性能瓶颈和常见问题。
关注行业动态和技术更新:
- 定期查阅相关技术博客、参加社区讨论,保持对最新技术和最佳实践的关注。
- 实践最新的大数据处理技术和工具,如Flink、Kubernetes等。
通过上述学习路径,你可以逐步建立起对大数据技术栈的理解,并能够独立完成从平台搭建到数据分析再到结果可视化的整个流程。每个阶段都应结合实际动手练习来加深理解和记忆,确保能够独立完成相应的任务。同时,保持对新技术的好奇心和探索精神,不断学习和进步。
[up主专用,视频内嵌代码贴在这]
喜欢这篇文章的人也看了